I fail to understand some options in the dumpBackup.php maintenance script of Mediawiki.
What is the effect of --include-files? In my test wiki, dumpBackup.php --current --include-files and dumpBackup.php --current both contain the pages of the File: namespace and I see no difference.
What is the effect of --uploads? In my test wiki I see that the xml file contains a tiny bit more of xml but, to me, it looks like this is all information which is there already as part of the File: page. What is the use of this flag?
When I add both --include-files and --uploads I get the next surprise. I actually expected the combined effect of both options, but what I get is the file content of the uploaded files and the upload record. Why did I not get the file contents when I used --include-files alone?
When I use only --include-files and --uploads but no --current I would have expected to get the content of the uploaded files and the upload record (and none of the other pages). However ,I get the warning no valid action specified and no further information at all
I am completely confused since I do not understand the logic behind all of this.
Software: Octave v7.1.0
There seems to be no option of defining the page size while doing publish ("FILE", "pdf") . The manual for pdf is: 11.11.1 docs.octave/.../Publish.
It's kinda surprising as it's a one word addition to the output TeX file : a4paper. I can do this manually each time I publish but being able to specify it somehow within the publish function would be awesome.
Surprisingly, there are plenty options for specifying page size in figures and images. Search for papertype at: 15.3.3.2 docs.octave/.../Figure-Properties
I searched with "Matlab" and found this page, and it fetched the results for "Matlab Report Generator" mlreportgen which seems a different thing.
I'd be interested to listen about other ways of doing it automatically too (like adding that word in TeX file via shell scripting and text string manipulation maybe).
As directed by #cris-luengo in the pointer comment to the linked manual, one solution can be to edit (or create) the function files (to used by the publish function) with the desired changes to specify the paper size.
The function files location can be found by:
opening the function file in octave gui and then proceeding from there:
edit (fullfile (fileparts (which ("publish")), "private", "__publish_html_output__.m"))
or, executing the following in octave REPL/command line:
fullfile (fileparts (which ("publish")), "private")
There, among other files, 2 files will be:
__publish_html_output__.m
__publish_latex_output__.m
Edit the _latex_ containing file to add ,a4paper (or other predefined size in latex) alongwith 10pt in the line '\documentclass[10pt]{article}',, optionally with a comment in a proceeding newline as a reminder that you added it, something like: '% Modification: specify a4paper',
If pdf format were directly specified as a new function file, then I'd have preferred to modify its copy and calling that directly in publish(), but since the publish pdf eventually calls publish latex, so, the only option at hand in this method seems to edit the original publish latex function file itself.
Is there any way to render LaTex in README.md in a GitHub repository? I've googled it and searched on stack overflow but none of the related answers seems feasible.
For short expresions and not so fancy math you could use the inline HTML to get your latex rendered math on codecogs and then embed the resulting image. Here an example:
- <img src="https://latex.codecogs.com/gif.latex?O_t=\text { Onset event at time bin } t " />
- <img src="https://latex.codecogs.com/gif.latex?s=\text { sensor reading } " />
- <img src="https://latex.codecogs.com/gif.latex?P(s | O_t )=\text { Probability of a sensor reading value when sleep onset is observed at a time bin } t " />
Which should result in something like the next
Update: This works great in eclipse but not in github unfortunately. The only work around is the next:
Take your latex equation and go to http://www.codecogs.com/latex/eqneditor.php, at the bottom of the area where your equation appears displayed there is a tiny dropdown menu, pick URL encoded and then paste that in your github markdown in the next way:
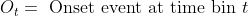
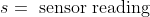
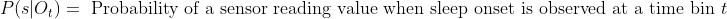
I upload repositories with equations to Gitlab because it has native support for LaTeX in .md files:
```math
SE = \frac{\sigma}{\sqrt{n}}
```
The syntax for inline latex is $`\sqrt{2}`$.
Gitlab renders equations with JavaScript in the browser instead of showing images, which improves the quality of equations.
More info here.
Let's hope Github will implement this as well in the future.
My trick is to use the Jupyter Notebook.
GitHub has built-in support for rendering .ipynb files. You can write inline and display LaTeX code in the notebook and GitHub will render it for you.
Here's a sample notebook file: https://gist.github.com/cyhsutw/d5983d166fb70ff651f027b2aa56ee4e
Readme2Tex
I've been working on a script that automates most of the cruft out of getting LaTeX typeset nicely into Github-flavored markdown: https://github.com/leegao/readme2tex
There are a few challenges with rendering LaTeX for Github. First, Github-flavored markdown strips most tags and most attributes. This means no Javascript based libraries (like Mathjax) nor any CSS styling.
The natural solution then seems to be to embed images of precompiled equations. However, you'll soon realize that LaTeX does more than just turning dollar-sign enclosed formulas into images.
Simply embedding images from online compilers gives this really unnatural look to your document. In fact, I would argue that it's even more readable in your everyday x^2 mathematical slang than jumpy .
I believe that making sure that your documents are typeset in a natural and readable way is important. This is why I wrote a script that, beyond compiling formulas into images, also ensures that the resulting image is properly fitted and aligned to the rest of the text.
For example, here is an excerpt from a .md file regarding some enumerative properties of regular expressions typeset using readme2tex:
As you might expect, the set of equations at the top is specified by just starting the corresponding align* environment
**Theorem**: The translation $[\![e]\!]$ given by
\begin{align*}
...
\end{align*}
...
Notice that while inline equations ($...$) run with the text, display equations (those that are delimited by \begin{ENV}...\end{ENV} or $$...$$) are centered. This makes it easy for people who are already accustomed to LaTeX to keep being productive.
If this sounds like something that could help, make sure to check it out. https://github.com/leegao/readme2tex
Since May 2022, this has been officially supported:
Inline:
Where $x = 0$, evaluate $x + 1$
Blocks:
Where
$$x = 0$$
Evaluate
$$x + 1$$
One can also use this online editor: https://www.codecogs.com/latex/eqneditor.php which generates SVG files on the fly. You can put a link in your document like this:
 which results in:
.
I test some solution proposed by others and I would like to recommend TeXify created and proposed in comment by agurodriguez and further described by Tom Hale - I would like develop his answer and give some reason why this is very good solution:
TeXify is wrapper of Readme2Tex (mention in Lee answer). To use Readme2Tex you must install a lot of software in your local machine (python, latex, ...) - but TeXify is github plugin so you don't need to install anything in your local machine - you only need to online installation that plugin in you github account by pressing one button and choose repositories for which TeXify will have read/write access to parse your tex formulas and generate pictures.
When in your repository you create or update *.tex.md file, the TeXify will detect changes and generate *.md file where latex formulas will be exchanged by its pictures saved in tex directory in your repo. So if you create README.tex.md file then TeXify will generate README.md with pictures instead tex formulas. So parsing tex formulas and generate documentation is done automagically on each commit&push :)
Because all your formulas are changed into pictures in tex directory and README.md file use links to that pictures, you can even uninstall TeXify and all your old documentation will still works :). The tex directory and *.tex.md files will stay on repository so you have access to your original latex formulas and pictures (you can also safely store in tex directory your other documentation pictures "made by hand" - TeXify will not touch them).
You can use equations latex syntax directly in README.tex.md file (without loosing .md markdown syntax) which is very handy. Julii in his answer proposed to use special links (with formulas) to external service e.g . http://latex.codecogs.com/gif.latex?s%3D%5Ctext%20%7B%20sensor%20reading%20%7D which is good however has some drawbacks: the formulas in links are not easy (handy) to read and update, and if there will be some problem with that third-party service your old documentation will stop work... In TeXify your old documentation will works always even if you uninstall that plugin (because all your pictures generated from latex formulas are stay in repo in tex directory).
The Yuchao Jiang in his answer, proposed to use Jupyter Notebook which is also nice however have som drawbacks: you cannot use formulas directly in README.md file, you need to make link there to other file *.ipynb in your repo which contains latex (MathJax) formulas. The file *.ipynb format is JSON which is not handy to maintain (e.g. Gist don't show detailed error with line number in *.ipynb file when you forgot to put comma in proper place...).
Here is link to some of my repo where I use TeXify for which documentation was generated from README.tex.md file.
Update
Today 2020.12.13 I realised that TeXify plugin stop working - even after reinstallation :(
For automatic conversion upon push to GitHub, take a look at the TeXify app:
GitHub App that looks in your pushes for files with extension *.tex.md and renders it's TeX expressions as SVG images
How it works (from the source repository):
Whenever you push TeXify will run and seach for *.tex.md files in your last commit. For each one of those it'll run readme2tex which will take LaTeX expressions enclosed between dollar signs, convert it to plain SVG images, and then save the output into a .md extension file (That means that a file named README.tex.md will be processed and the output will be saved as README.md). After that, the output file and the new SVG images are then commited and pushed back to your repo.
I just published a new version of xhub, a browser extension that renders LaTeX (and other things) in GitHub pages.
Cons:
You have to install the extension once.
Pros:
No need to set up anything.
Just write Markdown with math
Display math:
```math
e^{i\pi} + 1 = 0
```
and line math $`a^2 + b^2 = c^2`$.
(Syntax like on GitLab.)
Works on light and dark background. (Math has text-color)
You can copy-and-paste the math just like text
As an example, check out this GitHub README:
You can get a continuous integration service (e.g. Travis CI) to render LaTeX and commit results to github. CI will deploy a "cloud" worker after each new commit. The worker compiles your document into pdf and either cuses ImageMagick to convert it to an image or uses PanDoc to attempt LaTeX->HTML conversion where success may vary depending on your document. Worker then commits image or html to your repository from where it can be shown in your readme.
Sample TravisCi config that builds a PDF, converts it to a PNG and commits it to a static location in your repo is pasted below. You would need to add a line that fetches pdfconverts PDF to an image
sudo: required
dist: trusty
os: linux
language: generic
services: docker
env:
global:
- GIT_NAME: Travis CI
- GIT_EMAIL: builds#travis-ci.org
- TRAVIS_REPO_SLUG: your-github-username/your-repo
- GIT_BRANCH: master
# I recommend storing your GitHub Access token as a secret key in a Travis CI environment variable, for example $GH_TOKEN.
- secure: ${GH_TOKEN}
script:
- wget https://raw.githubusercontent.com/blang/latex-docker/master/latexdockercmd.sh
- chmod +x latexdockercmd.sh
- "./latexdockercmd.sh latexmk -cd -f -interaction=batchmode -pdf yourdocument.tex -outdir=$TRAVIS_BUILD_DIR/"
- cd $TRAVIS_BUILD_DIR
- convert -density 300 -quality 90 yourdocument.pdf yourdocument.png
- git checkout --orphan $TRAVIS_BRANCH-pdf
- git rm -rf .
- git add -f yourdoc*.png
- git -c user.name='travis' -c user.email='travis' commit -m "updated PDF"
# note we are again using GitHub access key stored in the CI environment variable
- git push -q -f https://your-github-username:$GH_TOKEN#github.com/$TRAVIS_REPO_SLUG $TRAVIS_BRANCH-pdf
notifications:
email: false
This Travis Ci configuration launches a Ubuntu worker downloads a latex docker image, compiles your document to pdf and commits it to a branch called branchanme-pdf.
For more examples see this github repo and its accompanying sx discussion, PanDoc example,
https://dfm.io/posts/travis-latex/, and this post on Medium.
I have been looking around and found that this answer in another question works best for me. i.e. use githubcontent math renderer, e.g. to display:
Use this link
Beware of the latex needs to be url encoded, but otherwise work quite well for me.
If you are having issues with https://www.codecogs.com/latex/eqneditor.php, I found that https://alexanderrodin.com/github-latex-markdown/ worked for me. It generates the Markdown code you need, so you just cut and paste it into your README.md document.
You may also take a look on my tool latexMarkdown2Markdown which convert LaTeX to SVG and generate a table of content with chapter numbering.
Good news!
According to this blogpost, now GitHub supports Mathjax in readme files.
You can use in-line LaTeX inspired syntax using $ delimiters, or in-blocks using $$ delimiters.
Writing inline expressions:
This sentence uses $ delimiters to show math inline:
$\sqrt{3x-1}+(1+x)^2$
Writing expressions as blocks:
The Cauchy-Schwarz Inequality
$$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2
\right) \left( \sum_{k=1}^n b_k^2 \right)$$
Source: https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/writing-mathematical-expressions
You can use markdowns, e.g.
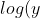=\beta_0&space;+&space;\beta_1&space;x&space;+&space;u)
Code can be typed here: https://www.codecogs.com/latex/eqneditor.php.
Edit: As germanium pointed out, it does not work for README.md but other git pages though no explanation is available.
My quick solution is this
step 1. Add latex to your .md file
$$x=\sqrt{2}$$
Note: math eqns must be in $$...$$ or \\(... \\).
step 2. Add the following to your scripts.html or theme file (append this code at the end)
<script type="text/javascript" async
src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-MML-AM_CHTML">
Done!. See your eq. by loading the page.
I have been asked to update a system where header information gets injected into a tif via a 3rd party console application. I don't need to worry about that bit.
The part I have been asked to look at it the merge process that generates the header information.
The current file generated by the process is assumed as correct, before I make any changes, so I want to add this as an approved result, from that I can then check that the changes I make will alter the file as expected.
I thought this would be a good opportunity to look at using ApprovalTests
The problem I have is that for what ever reason the links to the videos are considered corruptible (Possibly show me kittens jumping into boxes or something, which will stop me working, which ironically means I slow down my work done because I cannot see any help videos).
What I have been looking at is the Approvals.Verify and Approvals.VerifyFile extensions.
But what appears to be happening is confusing me.
using VerifyFile creates a received file, but the contents of the file are just a line the name of the file I have asked it to verify.
using Verify(new FileInfo("FileNameHere")) does not appear to generate the received file that I need to flag as approved, but the test does return saying that it cannot find the approved tif file.
I am probably using VerifyFile completely wrong and might be looking at using Verify wrong as well.
useful info?
Might be useful to know, that as this is a legacy application, running as a windows service, I have wrapped the service in a harness that allows me to call the routines, so the files are physically being written elsewhere on the machine outside of my control (well there is a config, but the return of the service I call generates a file in a fixed location if it is successful). I have tried copying that into the Unit Test project, but that doesn't appear to help.
Verify(File) and VerifyFile(string) are both meant to verify an existing file. As such they merely setting the received file to the file you pass in. You will still need to move/approval/create the approved file.
Here is the pseudo code and process.
[UseReporter(typeof(DiffReporter), typeof(ClipboardReporter)]
public void TestTiff()
{
string tif = YourProcessToCreateTifFile();
Approvals.VerifyFile(tif);
}
[Note: if you don't have an image diff installed, like TortoiseDiff, you might want to use the FileLauncherReporter]
Run this, once you get the result, move the file over by pasting your clipboard into a cmd window.
It will move the temporary tif to your test directory with the name ClassName.TestTiff.approved.tif
After that the test should pass until something changes.
Happy Testing!
firstly I'll give some background regarding the situation.
I have a website containing approximately 56k pages each page contain a mapped sketch of a machine part. this machine part is made out of smaller parts which are outlined in the image and hold a certain number. when you hover over the numbers a box with the part item code shows up.
I order parts according to this item codes but recently a lot of the items codes have changed, therefore I am looking for a solution.
now I own a database with data on all the 56k parts and I want to link the relevant webpage to each record according to the name of the part(a column in my database), the problem is that the webpages names has no logic name that could connect with the part name in any way but the image that is displayed in the page has the exact name of the part.
I want to rename all the html files I has according to the Images displayed within them. how can I achieve that without renaming all the 56k pages manually?
additionally how can I add the links to all the 56k pages automatically to my database after all the above is done?
Thank you for your patience I know it was long.
If you have a *nix shell, then a simple egrep will get you far
egrep "<img src=\".*\"" -r . > list
The regexp would have to be adapted to match the part you are looking for of course.
You could easily to some search/replace in the resulting list to create a batch script that will do all the renaming for you.
Pick your favorite scripting language and parse each html file to find the image name to use in renaming the file. Personally I would use Perl as it makes parsing the files and updating a database at the same time with the URL easy.