Is there any way to render LaTex in README.md in a GitHub repository? I've googled it and searched on stack overflow but none of the related answers seems feasible.
For short expresions and not so fancy math you could use the inline HTML to get your latex rendered math on codecogs and then embed the resulting image. Here an example:
- <img src="https://latex.codecogs.com/gif.latex?O_t=\text { Onset event at time bin } t " />
- <img src="https://latex.codecogs.com/gif.latex?s=\text { sensor reading } " />
- <img src="https://latex.codecogs.com/gif.latex?P(s | O_t )=\text { Probability of a sensor reading value when sleep onset is observed at a time bin } t " />
Which should result in something like the next
Update: This works great in eclipse but not in github unfortunately. The only work around is the next:
Take your latex equation and go to http://www.codecogs.com/latex/eqneditor.php, at the bottom of the area where your equation appears displayed there is a tiny dropdown menu, pick URL encoded and then paste that in your github markdown in the next way:
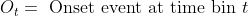
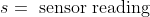
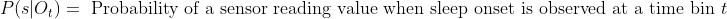
I upload repositories with equations to Gitlab because it has native support for LaTeX in .md files:
```math
SE = \frac{\sigma}{\sqrt{n}}
```
The syntax for inline latex is $`\sqrt{2}`$.
Gitlab renders equations with JavaScript in the browser instead of showing images, which improves the quality of equations.
More info here.
Let's hope Github will implement this as well in the future.
My trick is to use the Jupyter Notebook.
GitHub has built-in support for rendering .ipynb files. You can write inline and display LaTeX code in the notebook and GitHub will render it for you.
Here's a sample notebook file: https://gist.github.com/cyhsutw/d5983d166fb70ff651f027b2aa56ee4e
Readme2Tex
I've been working on a script that automates most of the cruft out of getting LaTeX typeset nicely into Github-flavored markdown: https://github.com/leegao/readme2tex
There are a few challenges with rendering LaTeX for Github. First, Github-flavored markdown strips most tags and most attributes. This means no Javascript based libraries (like Mathjax) nor any CSS styling.
The natural solution then seems to be to embed images of precompiled equations. However, you'll soon realize that LaTeX does more than just turning dollar-sign enclosed formulas into images.
Simply embedding images from online compilers gives this really unnatural look to your document. In fact, I would argue that it's even more readable in your everyday x^2 mathematical slang than jumpy .
I believe that making sure that your documents are typeset in a natural and readable way is important. This is why I wrote a script that, beyond compiling formulas into images, also ensures that the resulting image is properly fitted and aligned to the rest of the text.
For example, here is an excerpt from a .md file regarding some enumerative properties of regular expressions typeset using readme2tex:
As you might expect, the set of equations at the top is specified by just starting the corresponding align* environment
**Theorem**: The translation $[\![e]\!]$ given by
\begin{align*}
...
\end{align*}
...
Notice that while inline equations ($...$) run with the text, display equations (those that are delimited by \begin{ENV}...\end{ENV} or $$...$$) are centered. This makes it easy for people who are already accustomed to LaTeX to keep being productive.
If this sounds like something that could help, make sure to check it out. https://github.com/leegao/readme2tex
Since May 2022, this has been officially supported:
Inline:
Where $x = 0$, evaluate $x + 1$
Blocks:
Where
$$x = 0$$
Evaluate
$$x + 1$$
One can also use this online editor: https://www.codecogs.com/latex/eqneditor.php which generates SVG files on the fly. You can put a link in your document like this:
 which results in:
.
I test some solution proposed by others and I would like to recommend TeXify created and proposed in comment by agurodriguez and further described by Tom Hale - I would like develop his answer and give some reason why this is very good solution:
TeXify is wrapper of Readme2Tex (mention in Lee answer). To use Readme2Tex you must install a lot of software in your local machine (python, latex, ...) - but TeXify is github plugin so you don't need to install anything in your local machine - you only need to online installation that plugin in you github account by pressing one button and choose repositories for which TeXify will have read/write access to parse your tex formulas and generate pictures.
When in your repository you create or update *.tex.md file, the TeXify will detect changes and generate *.md file where latex formulas will be exchanged by its pictures saved in tex directory in your repo. So if you create README.tex.md file then TeXify will generate README.md with pictures instead tex formulas. So parsing tex formulas and generate documentation is done automagically on each commit&push :)
Because all your formulas are changed into pictures in tex directory and README.md file use links to that pictures, you can even uninstall TeXify and all your old documentation will still works :). The tex directory and *.tex.md files will stay on repository so you have access to your original latex formulas and pictures (you can also safely store in tex directory your other documentation pictures "made by hand" - TeXify will not touch them).
You can use equations latex syntax directly in README.tex.md file (without loosing .md markdown syntax) which is very handy. Julii in his answer proposed to use special links (with formulas) to external service e.g . http://latex.codecogs.com/gif.latex?s%3D%5Ctext%20%7B%20sensor%20reading%20%7D which is good however has some drawbacks: the formulas in links are not easy (handy) to read and update, and if there will be some problem with that third-party service your old documentation will stop work... In TeXify your old documentation will works always even if you uninstall that plugin (because all your pictures generated from latex formulas are stay in repo in tex directory).
The Yuchao Jiang in his answer, proposed to use Jupyter Notebook which is also nice however have som drawbacks: you cannot use formulas directly in README.md file, you need to make link there to other file *.ipynb in your repo which contains latex (MathJax) formulas. The file *.ipynb format is JSON which is not handy to maintain (e.g. Gist don't show detailed error with line number in *.ipynb file when you forgot to put comma in proper place...).
Here is link to some of my repo where I use TeXify for which documentation was generated from README.tex.md file.
Update
Today 2020.12.13 I realised that TeXify plugin stop working - even after reinstallation :(
For automatic conversion upon push to GitHub, take a look at the TeXify app:
GitHub App that looks in your pushes for files with extension *.tex.md and renders it's TeX expressions as SVG images
How it works (from the source repository):
Whenever you push TeXify will run and seach for *.tex.md files in your last commit. For each one of those it'll run readme2tex which will take LaTeX expressions enclosed between dollar signs, convert it to plain SVG images, and then save the output into a .md extension file (That means that a file named README.tex.md will be processed and the output will be saved as README.md). After that, the output file and the new SVG images are then commited and pushed back to your repo.
I just published a new version of xhub, a browser extension that renders LaTeX (and other things) in GitHub pages.
Cons:
You have to install the extension once.
Pros:
No need to set up anything.
Just write Markdown with math
Display math:
```math
e^{i\pi} + 1 = 0
```
and line math $`a^2 + b^2 = c^2`$.
(Syntax like on GitLab.)
Works on light and dark background. (Math has text-color)
You can copy-and-paste the math just like text
As an example, check out this GitHub README:
You can get a continuous integration service (e.g. Travis CI) to render LaTeX and commit results to github. CI will deploy a "cloud" worker after each new commit. The worker compiles your document into pdf and either cuses ImageMagick to convert it to an image or uses PanDoc to attempt LaTeX->HTML conversion where success may vary depending on your document. Worker then commits image or html to your repository from where it can be shown in your readme.
Sample TravisCi config that builds a PDF, converts it to a PNG and commits it to a static location in your repo is pasted below. You would need to add a line that fetches pdfconverts PDF to an image
sudo: required
dist: trusty
os: linux
language: generic
services: docker
env:
global:
- GIT_NAME: Travis CI
- GIT_EMAIL: builds#travis-ci.org
- TRAVIS_REPO_SLUG: your-github-username/your-repo
- GIT_BRANCH: master
# I recommend storing your GitHub Access token as a secret key in a Travis CI environment variable, for example $GH_TOKEN.
- secure: ${GH_TOKEN}
script:
- wget https://raw.githubusercontent.com/blang/latex-docker/master/latexdockercmd.sh
- chmod +x latexdockercmd.sh
- "./latexdockercmd.sh latexmk -cd -f -interaction=batchmode -pdf yourdocument.tex -outdir=$TRAVIS_BUILD_DIR/"
- cd $TRAVIS_BUILD_DIR
- convert -density 300 -quality 90 yourdocument.pdf yourdocument.png
- git checkout --orphan $TRAVIS_BRANCH-pdf
- git rm -rf .
- git add -f yourdoc*.png
- git -c user.name='travis' -c user.email='travis' commit -m "updated PDF"
# note we are again using GitHub access key stored in the CI environment variable
- git push -q -f https://your-github-username:$GH_TOKEN#github.com/$TRAVIS_REPO_SLUG $TRAVIS_BRANCH-pdf
notifications:
email: false
This Travis Ci configuration launches a Ubuntu worker downloads a latex docker image, compiles your document to pdf and commits it to a branch called branchanme-pdf.
For more examples see this github repo and its accompanying sx discussion, PanDoc example,
https://dfm.io/posts/travis-latex/, and this post on Medium.
I have been looking around and found that this answer in another question works best for me. i.e. use githubcontent math renderer, e.g. to display:
Use this link
Beware of the latex needs to be url encoded, but otherwise work quite well for me.
If you are having issues with https://www.codecogs.com/latex/eqneditor.php, I found that https://alexanderrodin.com/github-latex-markdown/ worked for me. It generates the Markdown code you need, so you just cut and paste it into your README.md document.
You may also take a look on my tool latexMarkdown2Markdown which convert LaTeX to SVG and generate a table of content with chapter numbering.
Good news!
According to this blogpost, now GitHub supports Mathjax in readme files.
You can use in-line LaTeX inspired syntax using $ delimiters, or in-blocks using $$ delimiters.
Writing inline expressions:
This sentence uses $ delimiters to show math inline:
$\sqrt{3x-1}+(1+x)^2$
Writing expressions as blocks:
The Cauchy-Schwarz Inequality
$$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2
\right) \left( \sum_{k=1}^n b_k^2 \right)$$
Source: https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/writing-mathematical-expressions
You can use markdowns, e.g.
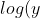=\beta_0&space;+&space;\beta_1&space;x&space;+&space;u)
Code can be typed here: https://www.codecogs.com/latex/eqneditor.php.
Edit: As germanium pointed out, it does not work for README.md but other git pages though no explanation is available.
My quick solution is this
step 1. Add latex to your .md file
$$x=\sqrt{2}$$
Note: math eqns must be in $$...$$ or \\(... \\).
step 2. Add the following to your scripts.html or theme file (append this code at the end)
<script type="text/javascript" async
src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-MML-AM_CHTML">
Done!. See your eq. by loading the page.
I previously used an old CMS.
I moved to wordpress and I've done a lot of work, but I still have in my very old articles 1000+ internal links pointing to old urls.
I've set up redirects, but I would like to actually replace / delete the very old internal linking in the wordpress database.
I have 3 types of old linking :
/articles.php?lng=fr&pg=425 .......... so like /articles.php?stuff
/news.php?lng=fr&pg=1827 .......... so like /news.php?stuff
/2456-actualite .......... so like /id-actualite
I believe that "Search and replace" and "Better search and replace", both Wordpress plugins are only dealing with exact urls, while the ids are dynamic.
How would you delete those all links in the database, but keeping the hypertext of those links?
Thanks !
Have you tried using WP Cli?
It's a very powerful tool for this kind of problems by running some commands on your server.
Example:
# Search and replace but skip one column
$ wp search-replace 'http://example.dev' 'http://example.com' --skip-columns=guid
Have a look more on their search-replace command.
It is probably impossible to change each URL by hand.. much better way is to use something like this "https://wordpress.org/plugins/search-and-replace/" to replace all URLs you need in the database. - This does not only deal with urls but with any other text too.
I want to get all URLs from specific page in Bash.
This problem is already solved here: Easiest way to extract the urls from an html page using sed or awk only
The trick, however, is to parse relative links into absolute ones. So if http://example.com/ contains links like:
About us
<script type="text/javascript" src="media/blah.js"></a>
I want the results to have following form:
http://example.com/about.html
http://example.com/media/blah.js
How can I do so with as little dependencies as possible?
Simply put, there is no simple solution. Having little dependencies leads to unsightly code, and vice versa: code robustness leads to higher dependency requirements.
Having this in mind, below I describe a few solutions and sum them up by providing pros and cons of each one.
Approach 1
You can use wget's -k option together with some regular expressions (read more about parsing HTML that way).
From Linux manual:
-k
--convert-links
After the download is complete, convert the links in the document to
make them suitable for local viewing.
(...)
The links to files that have not been downloaded by Wget will be
changed to include host name and absolute path of the location they
point to.
Example: if the downloaded file /foo/doc.html links to /bar/img.gif
(or to ../bar/img.gif), then the link in doc.html will be modified to
point to http://hostname/bar/img.gif.
An example script:
#wget needs a file in order for -k to work
tmpfil=$(mktemp);
#-k - convert links
#-q - suppress output
#-O - redirect output to given file
wget http://example.com -k -q -O "$tmpfil";
#-o - print only matching parts
#you could use any other popular regex here
grep -o "http://[^'\"<>]*" "$tmpfil"
#remove unnecessary file
rm "$tmpfil"
Pros:
Works out of the box on most systems, assuming you have wget installed.
In most cases, this will be sufficient solution.
Cons:
Features regular expressions, which are bound to break on some exotic pages due to HTML hierarchical model standing below regular expressions in Chomsky hierarchy.
You cannot pass a location in your local file system; you must pass working URL.
Approach 2
You can use Python together with BeautifulSoup. An example script:
#!/usr/bin/python
import sys
import urllib
import urlparse
import BeautifulSoup
if len(sys.argv) <= 1:
print >>sys.stderr, 'Missing URL argument'
sys.exit(1)
content = urllib.urlopen(sys.argv[1]).read()
soup = BeautifulSoup.BeautifulSoup(content)
for anchor in soup.findAll('a', href=True):
print urlparse.urljoin(sys.argv[1], anchor.get('href'))
And then:
dummy:~$ ./test.py http://example.com
Pros:
It's the correct way to handle HTML, since it's properly using fully-fledged parser.
Exotic output is very likely going to be handled well.
With small modifications, this approach works for files, not URLs only.
With small modifications, you might even be able to give your own base URL.
Cons:
It needs Python.
It needs Python with custom package.
You need to manually handle tags and attributes like <img src>, <link src>, <script src> etc (which isn't presented in the script above).
Approach 3
You can use some features of lynx. (This one was mentioned in the answer you provided in your question.) Example:
lynx http://example.com/ -dump -listonly -nonumbers
Pros:
Very concise usage.
Works well with all kind of HTML.
Cons:
You need Lynx.
Although you can extract links from files as well, you cannot control the base URL and you end up with file://localhost/ links. You can fix this using ugly hacks like manual inserting <base href=""> tag into HTML.
Another option is my Xidel (XQuery/Webscraper):
For all normal links:
xidel http://example.com/ -e '//a/resolve-uri(#href)'
For all links and srcs:
xidel http://example.com/ -e '(//#href, //#src)/resolve-uri(.)'
With rr-'s format:
Pros :
Very concise usage.
Works well with all kind of HTML.
It's the correct way to handle HTML, since it's properly using fully-fledged parser.
Works for files and urls
You can give your own base URL. (with resolve-uri(#href, "baseurl"))
No dependancies except Xidel (except openssl, if you also have https urls)
Cons:
You need Xidel, which is not contained in any standard repository
Why not simply this ?
re='(src|href)='
baseurl='example.com'
wget -O- "http://$baseurl" | awk -F'(src|href)=' -F\" "/$re/{print $baseurl\$2}"
you just need wget and awk.
Feel free to improve the snippet a bit if you have both relative & absolute urls at the same time.
I'm writing a shell script which tracks the changes of a website and emails me with the contents of the change if one occurs. The idea is to use wget to grab a copy of the html and compare it to the version from the last time the script ran. Wget works fine to save the html file but I'm having trouble comparing the files. The trouble is that I'm only interested in changes in the html file's plain text, not the code, links, etc.
Diff works to find all the changes in the two files but it ALWAYS returns changes even when the plain text is identical. This is because each link on the site has a corresponding authenticity token that differs each time the page is accessed. In order to diff only the lines that include plain text I'm attempting to filter it to exclude any line that begins with "<" OR "(any_amount_of_spaces)<". I've looked at the diff man page but I can't seem to find an operator that will do what I need. I don't know much about REGEX but would that work with diff -I for this?
Thanks!
You could use lynx -dump to render the pages and feed those to diff, but since you are not interested in links you would need to get rid of the References section that this yields (with e.g. awk) rendering this a not-so-robust solution (but maybe good enough for your use case).
If you don't mind using something 3rd-party go for html2text:
diff <(html2text before.html) <(html2text after.html)
PS: There are two different programs called html2text.
I tend to write a good amount of documentation so the MediaWiki format to me is easy for me to understand plus it saves me a lot of time than having to write traditional HTML. I, however, also write a blog and find that switching from keyboard to mouse all the time to input the correct tags for HTML adds a lot of time. I'd like to be able to write my articles in Mediawiki syntax and then convert it to HTML for use on my blog.
I've tried Google-ing but must need better nomenclature as surprisingly I haven't been able to find anything.
I use Linux and would prefer to do this from the command line.
Any one have any thoughts or ideas?
The best would be to use MediaWiki parser. The good news is that MediaWiki 1.19 will provide a command line tool just for that!
Disclaimer: I wrote that tool.
The script is maintenance/parse.php some usage examples straight from the source code:
Entering text yourself, ending it with Control + D:
$ php maintenance/parse.php --title foo
''[[foo]]''^D
<p><i><strong class="selflink">foo</strong></i>
</p>
$
The usual file input method:
$ echo "'''bold'''" > /tmp/foo.txt
$ php maintenance/parse.php /tmp/foo.txt
<p><b>bold</b>
</p>$
And of course piping to stdin:
$ cat /tmp/foo | php maintenance/parse.php
<p><b>bold</b>
</p>$
as of today you can get the script from http://svn.wikimedia.org/svnroot/mediawiki/trunk/phase3/maintenance/parse.php and place it in your maintenance directory. It should work with MediaWiki 1.18
The script will be made available with MediaWiki 1.19.0.
Looked into this a bit and think that a good route to take here would be to learn to a general markup language like restucturedtext or markdown and then be able to convert from there. Discovered a program called pandoc that can convert either of these to HTML and Mediawiki. Appreciate the help.
Example:
pandoc -f mediawiki -s myfile.mediawiki -o myfile.html -s
This page lists tons of MediaWiki parsers that you could try.